👷📚 เล่าให้ฟัง: ย้ายสายจาก Software Engineer มาเป็น Data Engineer สามเดือนแรก


โพสนี้เหมือนเป็นภาคต่อจาก ลาออกยังไงไม่ให้บ้านบึ้ม ครับคือกระบวนการต่างๆ มันเริ่มตั้งแต่เรายังทำงานในที่เก่าอยู่ โพสนี้เลยจะมาเล่าให้ฟังคร่าวๆ ว่าก่อนจะเริ่มงาน Data Engineer และที่ผ่านมาสามเดือนนี้ผมผ่านอะไรมาบ้าง พร้อมวิธีการเอาตัวรอดในแบบของผมเองละกัน
💡 Disclaimer: ความเห็นต่างๆ ในโพสนี้เป็นความคิดเห็นส่วนตัว ไม่ได้เกี่ยวข้องกับบริษัทที่ผมทำงานอยู่ปัจจุบันแต่อย่างใดครับ
ก่อนเริ่มงาน 1 เดือน
จากตอนที่แล้วผมบอกไว้ว่ามันจะมีช่วงที่เรา lower your light ซึ่งเป็นเวลาที่ดีที่สุดที่เราจะเตรียมตัวกับงานใหม่ จังหวะนี้เป็นช่วงที่ผมหาข้อมูลงานใหม่ให้มากที่สุดครับ ซึ่งจากเท่าที่คุยตอนสัมภาษณ์ผมรู้แค่ว่า Tooling หลักคือ Dagster ช่วงแรกๆ ผมเลยดู Dagster เป็นหลักเลยซึ่ง ณ จุดนี้ถ้ามองย้อนไปผมบอกเลยว่า Tutorial ของ Dagster มันเป็นกับดักครับ 555 คือมันดูเหมือนจะเข้าใจง่าย job, ops, เขียนเทสได้ อะไรก็ว่าไป แต่ของจริงมันอยู่ใน Concept กับตัวอย่างใน GitHub ของ Dagster เองครับ อันนั้นคือถ้ากระโดดต่อมาจาก Tutorial ก็จะมีความช็อคน้ำหน่อยๆ แต่เดี๋ยว Dagster ผมมาเล่าต่อในอนาคต มีอีกหลายเรื่องเลยให้เล่าครับ

นอกจาก Dagster แล้วผมต้องขุดความทรงจำว่าเพื่อนร่วมงานผมในอนาคต (ซึ่งเป็นเพื่อนร่วมงานในปัจจุบัน) เค้าทำอะไรมาบ้าง ซึ่งโชคดีมากที่เค้าเคยเล่าไว้ใน LINE Developers Podcast ไว้ถึง 2 ตอนเลย เพราะใน Podcast นี้แนะนำไว้ชัดเจนเลยว่า เราควรจะรู้จัก Hadoop ecosystem นะ ซึ่งผมไต่ไปหลายบล็อกมาก ช่วงนั้นเพื่อจะอัพเดทความรู้ Hadoop ตัวเองที่ถูกแช่ไว้ตั้งแต่ปี 2013 ซึ่งในบรรดาบล็อกทั้งหมดที่ผมไล่อ่านมา ผมประทับใจบล็อก Good Old Days Hadoop นี้มากครับซึ่งเล่าประวัติ Hadoop ได้เห็นภาพมาก รวมถึงพูดถึง YARN, Spark ไว้นิดหน่อยด้วย ซึ่งตอนนั้นผมยังจับภาพไม่ได้เลยว่ามันเกี่ยวกันยังไง
💡 “Software Engineer ทุกคนเราอ่ะเป็น Data Engineer อยู่แล้ว เพียงแค่ความเข้มข้นในการเข้าไปจัดการข้อมูลของเรามันต่างกัน”
- ผมชอบประโยคนี้ของเพื่อนร่วมงานในอนาคตผมมาก
นอกจาก Podcast ข้างบนผมโชคดีอย่างนึงที่ผมพอจะรู้จักเพื่อนร่วมงานในอนาคตผมอีกคน ซึ่งผมก็ถามไปตรงๆ เลยว่าผมควรดูอะไรก่อนบ้างก็ได้รู้จัก Apache Spark มาซึ่งพอได้ยินแบบนั้นปั๊ป ผมกดเรียนคอร์ส Batch Data Pipeline with Spark แบบไม่ลังเลเลย แล้ว Live Project ของ Manning ดีอย่างนึงคือไม่ใช่แค่ก็อปโค้ดแปะแล้วรันได้ แต่จะคล้ายทำงานจริงๆ มากที่บอกว่า เราอยากได้แบบนี้แหละ แล้วก็มี resource guide ให้คร่าวๆ แต่เราต้องไปเปิด Doc API ของ Spark เองว่าจะใช้ฟังก์ชั่นอะไร มาทำให้งาน Ingestion, Cleaning data เป็นไปแบบที่เราต้องการ แล้วนอกจากนั้นยังมีพวก Tips อะไรแทรกอยู่ด้วยเหมือนเรามีเพื่อนร่วมงานระดับโลกคอยคุยกับเราผ่านตัวหนังสือไปอีก
แต่ยังไม่ทันได้เรียนจนจบคอร์สข้างบนผมก็มีโอกาสเจอเพื่อนร่วมงานในอนาคตผมอีกคน ซึ่งผมก็ถามแบบตรงๆ เหมือนเดิม แต่คำตอบที่ได้มาต่างกันคือผมน่าจะลองไปดู Apache Hive กับ Presto ดูซึ่งด้วยความที่เวลาเหลืออีกไม่กี่วันจะเริ่มงานละ ผมเลยลองดูหนังสือ Learn Hive in 1 Day ดู ซึ่งสำหรับคนจะไปดูนะฮะ ข้ามหนังสือเล่มนี้ไปเลยครับ เพราะผมซึ่งไปดู Spark มาก่อนหน้านี้บอกเลยว่าเล่มนี้ไม่ได้ให้ Concept อะไรใหม่ๆ กับเราเลย (แถมพิมพ์ผิดเยอะมากแบบน่ารำคาญ (น่าจะอ่าน Amazon Review ก่อน TT)) แต่อย่างน้อยก็เสียเวลาไม่ถึงวัน
ในส่วนของ Presto เราจะไม่สามารถเข้าใจมันได้เลย ถ้าเราไม่เข้าใจ Hive มาก่อนเพราะ Presto ยังต้องพึ่ง component สำคัญของ Hive อย่าง Metastore ในการทำความรู้จักกับข้อมูลที่เก็บอยู่ ซึ่งตอนเรารู้จัก Hive ใหม่ๆ เราคิดว่าว้าวแล้วนะ ที่มันมา Optimize ให้การทำ MPP บน HDFS มันง่ายขึ้นกว่าสมัย Map Reduce มากแล้วการเอา Compute ไปอยู่ใกล้ๆ Disk นี่ก็ว้าวแล้ว แต่พอรู้จัก Presto ก็จะว้าวไปอีกเพราะมัน Optimize ขึ้นมาอีกขั้นเพื่อ ad-hoc query โดยมาทำงานใน Memory แทน ซึ่งผมรู้ทั้งหมดนี่ผ่านลิ้งค์ต่อไปนี้ครับ [1][2][3][4]
จริงๆ ยังมี Source อีกหลายแหล่งไม่ว่าจะเป็น Data Engineer Cafe, Data Engineer Zoomcamp ฯลฯ ที่เป็นที่พึ่งให้ผมเตรียมตัวด้วย ซึ่งพอถึงจุดนี้เหลือเวลาไม่กี่วันหลังเริ่มงานผมบอกเลยว่าในหัวตอนนี้ทุกอย่างที่ผมเล่ามามันตีกันไปหมดมากๆ ซึ่งถ้าใครเคยมองมาวงการ Data Science/Engineering ก็น่าจะรู้สึกไม่ต่างจากผมว่าทุกอย่างมันถาโถม มันเยอะมากจนไม่รู้จะเริ่มจากตรงไหนดีแล้วในใจก็ยังรู้ว่ามันยังมี Unknow อีกมากที่ต้องไปเจอหน้างานถึงจะรู้ว่าอะไร
เดือนแรก
พอเข้ามาเดือนแรก ผมได้รับการบอกกล่าวเลยว่า Data Engineer ที่นี่น่าจะไม่เหมือนที่อื่นนะตาม Data Maturity ขององค์กร ซึ่งแรกๆ ผมก็ไม่ค่อยได้ยินใครพูดที่ไหนเรื่องนี้นอกจากกับเพื่อนร่วมงานผม จนกระทั่งเพิ่งเห็นพี่ทอยเขียนบล็อกนี้ เลยรู้ซึ้งว่าวิธีการแยกแบบนี้มันมาจากหนังสือเล่มนี้ ซึ่งพอมามองย้อนกลับไป เอ่อจริง เพราะตั้งแต่เดือนแรกไม่ใช่ผมกระโดดไปทำ Data pipeline เลย แต่ไปทำความเข้าใจว่า pyhive มันทำงานยังไงกับ Hive, Spark, Presto จนไปรู้จัก Thrift server ที่ทำงานอยู่ข้างหลัง รวมถึงไปทำความรู้จักกับ Hadoop ecosystem อีกครั้ง (แบบมีคนคุยด้วย)
แต่ก็ใช่ว่าจะไม่มีงาน Data pipeline เลย ซึ่งงานหนึ่งที่ Data Engineer ทุกคนที่นี่ได้ทำคือการ Migrate Dagster abstraction ของ data pipeline ให้มาใช้ตัวใหม่ครับ ซึ่งผมบอกเลยว่า การไปดูกับการมานั่งทำงานกับ production ready pipeline มันต่างกันเยอะมากครับ นอกจากจะต้องไปค้น Docs ว่า Abstraction ใหม่มัน migrate ยังไงบ้างตั้งแต่ระดับ repository, schedule เรื่อยไปจนถึง resource แล้ว support system, tooling, หรือ workflow ต่างๆ ก็ต้องไปทำความรู้จักกับมันเช่น GitOps, Earthly, หรือแม้กระทั่ง SQL ที่เหมือนจะรู้จักอยู่แล้ว แต่พอเห็นวิธีการเขียนแบบ CTEs รวมถึง Dialect ของแต่ละ Query engine ที่ต้องทำงานด้วยก็ตระหนักได้ว่าเรายังไม่รู้อะไรเลย
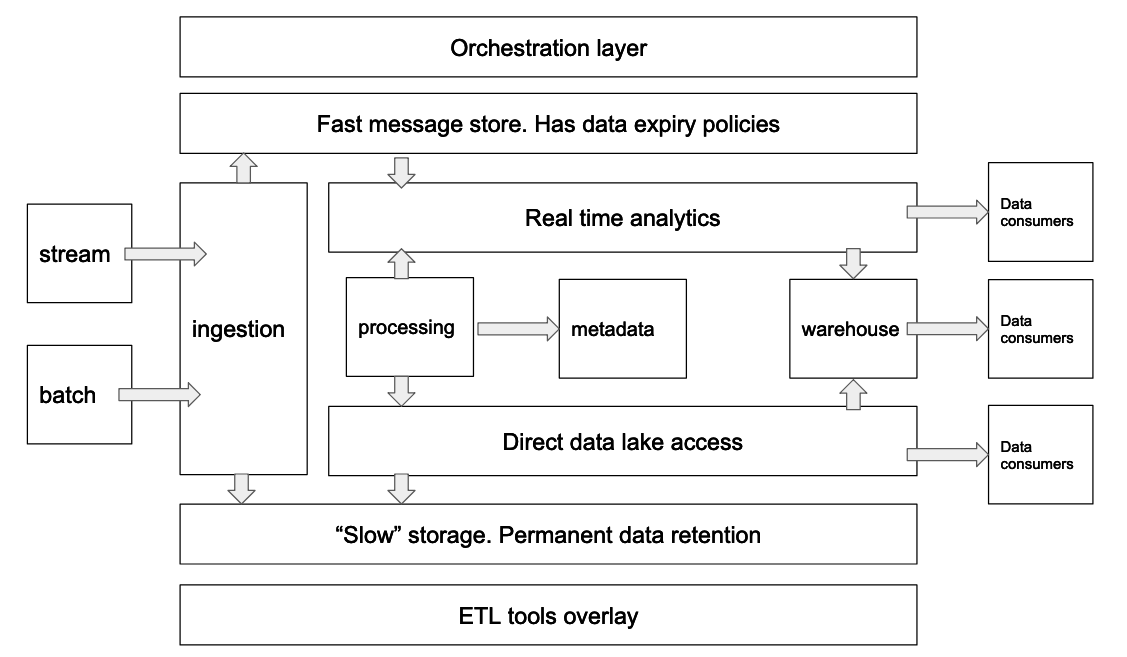
โชคดีที่เดือนแรกผมมีวันหยุดยาวอยู่กลางเดือนหลังจากไปทำงานได้อาทิตย์เดียว เลยเป็นช่วงเวลาที่กลับมาตั้งสติได้ดีมาก ซึ่งตัวช่วยทำให้ผมกลับมาเห็นภาพหลายๆ อย่างชัดขึ้นเป็นภาพข้างบน ต้องขอบคุณหนังสือ Designing Cloud Data Platforms เลยครับ เล่มนี้ช่วยดึงสติให้ผมกลับมาเห็น Data Platform ใน Mental model ได้ชัดเหมือนสมัยยังเป็น Software Engineer แล้วมองว่าแต่ละ components ของแอพมันคืออะไร มาทำหน้าที่อะไร ซึ่ง 3 บทแรกจะพาไป รู้จัก Data Platform ก่อน ส่วนบทที่เหลือในหนังสือจะพาไปเจาะลึกทั้ง tools, techniques ของแต่ละ component ตั้งแต่ Ingestion, Processing เรื่อยไปถึง Data Access ซึ่งส่วนตัวผมยังอ่านไม่จบ ถ้าจบแล้วก็น่าจะมีโอกาสมาเล่าให้ฟังกันในบล็อกนี้ครับ เรียกได้ว่าคัมภีร์คู่ใจผมเลยมาจนถึงทุกวันนี้
เดือนที่สอง
งานในช่วงเดือนที่สองมีความแตกต่างขึ้นไปนิดนึง เพราะพอเริ่มเข้าโปรเจ็คจะมีงานในส่วนของ Data Modeling กับ Data Exploration เพิ่มเข้ามา ในส่วนของ Data Modeling เรียกได้ว่าอาศัยประสบการณ์ Backend Engineer มาเอาตัวรอดไปได้ครับในการออกแบบ Schema ของ Data ที่เรา Provide ให้ Consumer ใช้ยังไงให้ตอบโจทย์ requirements และ Maintain ได้สบายไปพร้อมๆ กัน แต่ส่วน Data Exploration นี่เรียกได้ว่าเป็นประสบการณ์ที่แปลกใหม่มาก เพราะเราต้องไปตามหา Data ที่เราต้องการมาตอบโจทย์ Business requirements ความยากนอกจากต้องไปตะลุยทุ่ง Documents, Wiki เพื่อหา Data ที่ต้องการแล้ว ก็ต้องมา Verify ต่อว่าตอบโจทย์ที่เราต้องการจริงๆ มั้ยนะ หรือติด limitation อะไรด้วยรึเปล่า ซึ่งกินพลังชีวิตหนักมากทั้ง 2 ส่วนที่ผมว่าเลยครับ
ในส่วนของ Data pipeline ที่ยังต้องดูแลอยู่แต่พอเริ่มจะใช้ Dagster ได้อยู่มือขึ้น ก็เริ่มเห็นภาพว่าเห้ยการดูแล data pipeline อ่ะ มันไม่ต่างกับการดูแล Software อื่นๆ เลยนะ เพราะตัว pipeline มันมีอายุของมัน มีการ extend มีการ upgrade ฯลฯ เพราะฉะนั้น practices ต่างๆ ของ Software Engineering ในการสร้าง Maintainable software เข้ามาช่วยเยอะมากตอนนี้ครับ
เดือนที่สาม
พอเข้าเดือนที่สามมีโอกาสได้ไปแตะๆ งาน POC Platform บ้าง ผมมีโอกาสไปลอง POC ในส่วนเล็กๆ ที่ decoupling compute engine interface ออกมาโดยใช้ Apache Livy เป็นพื้นฐาน ซึ่งไองาน POC เล็กๆ ที่ว่าพาผมไปรู้จัก Hadoop, YARN, Spark เยอะขึ้นมากกว่าตอนที่ดูเองก่อนหน้านี้เยอะมากว่ามันคุยกันยังไงกว่าจะได้ processing, storage layer ใน Data Platform ขึ้นมาซักตัว
อีกสิ่งหนึ่งที่ค่อยๆ เห็นภาพชัดขึ้นแล้วค่อนข้างเป็น Pitfall หนึ่งของคนใช้งาน Dagster คือ Ops ไม่ใช่ function ซึ่งตอนแรกที่ได้ยินมาผมยังไม่เข้าใจ Dagster มากประโยคนี้เลยยังอยู่ในใจอยู่ แต่พอขึ้น data pipeline เส้นที่สองแล้วเริ่มรู้สึกว่าทำไมต้องมาทำซ้ำด้วยนะ เท่านั้นแหละเหมือนคนตรัสรู้เลย แล้วเส้นแบ่งมันนิดเดียวมากคือ Ops เราต้อง general ระดับนึงแล้วใช้ abstraction ของ Dagster ในการจัดการ input, output หรือ behavior ของ Ops นั้นแทน แล้วพอมองโลก Dagster ผ่านเลนส์นี้เท่านั้นแหละ ผมเห็นโอกาสเต็มไปหมดเลยครับและผมมั่นใจว่าพวกที่ทำ Tooling ในวงการ data ก็เห็นสิ่งนี้เหมือนกันมานานก่อนผมมาก เราเลยได้เห็น ความร่วมมือของ tool หลายๆ อย่างกับ Dagster เช่น Dagster x dbt, Dagster x Airbyte อะไรแบบนี้เป็นต้นครับ
คำแนะนำจากประสบการณ์ต๊อกต๋อยนี้
ประมาณนี้ครับประสบการณ์สามเดือนผม ยังคิดว่าตัวเองประสบการณ์น้อยมากในงาน Data Engineering และยังมีอะไรให้เรียนรู้เพิ่มอยู่เรื่อยๆ อีกในทุกๆ วัน แต่ถ้าพอมามองย้อนกลับไปถ้าจะมีอะไรแนะนำคนที่อยากจะย้ายมาทำงานสาย Data Engineering ผมพอจะแนะนำจากประสบการณ์น้อยนิดของผมได้ตามนี้เลยครับ
- อย่างแรกเลย มันมีความต่างเยอะมากระหว่างคนที่เป็น Consumer ของ Platform กับคนที่สร้าง Platform ผมเข้าใจภาพนี้ชัดมากถ้ามองย้อนไปตอนผมรู้จัก Spark ใหม่ๆ แล้วก็รู้สึกว่าเอ่อ มันก็ไม่ต่างจาก Pandas ที่เราคุ้นเคยมากนี่หว่า แต่พอต้องประกอบมันขึ้นมาจริงๆ แล้วโลกของ Spark นี่มันกว้างใหญ่โคตรๆ เลยครับ แค่เปลี่ยน Resource manager นี่โลกก็เปลี่ยนแล้ว เพราะฉะนั้นย้ำอีกครั้งว่า มันสำคัญมากที่เราจะต้องเข้าใจ Tooling ที่เราต้องทำงานหรือดูแลด้วยไม่ใช่แค่ใช้เป็น แต่เข้าใจเลยว่ามันทำงาน (ด้วยกัน) ได้ยังไง
- อย่างที่สองผมมาตกผลึกตอนต้องไปทำ Data Exploration นี่แหละครับ ด้วยความที่มันมีสิ่งที่เกิดขึ้นใหม่ๆ ในโลกของ Data ตลอดเวลา ไม่นับ Data Domain ที่เราต้องไปความเข้าใจด้วย สิ่งที่จะเกิดขึ้นตามมาคือ สิ่งที่เรารับรู้มันจะเยอะมาก จนหลายครั้งมันถาโถม วิธีการเอาตัวรอดจากตรงนี้ให้ได้คือ เราต้องจัดการความรู้ของเราเองให้เป็นครับ สามารถกลั่นความรู้ออกมาจากสิ่งที่รับรู้และต่อยอดเพื่อที่จะเข้าใจสิ่งใหม่ๆ ต่อได้ ซึ่งวิธีการที่ผมใช้หลักๆ คือจดครับและแน่นอนว่าเครื่องมือคู่ใจผมยังคงเป็น Notion ไม่ว่าใครจะชวนไปใช้ tooling ตัวไหนก็ตาม 555
- อย่างสุดท้าย ผมไปดู Live ของบอย BigData RPG หลายอาทิตย์ก่อนตอนกำลังดูประกาศรับสมัครงานสาย Data แล้วผมไปสะดุดใจกับคุณสมบัตินึงในประกาศคือ Self-Driven ซึ่งตอนที่ฟังแล้วมามองย้อนกลับไป มันจริงมาก เพราะพอถึงจุดหนึ่งหลังจากเราเริ่มเห็นภาพอะไรชัดขึ้นแล้ว ด้วยความที่ทะเลของงานในสาย Data Engineering มันเยอะมาก เราต้องเป็นคนตัดสินใจเองว่าอยากจะโฟกัสเรื่องอะไร โดยที่ยัง Align กับ Goal ของงานที่ทำอยู่ ต้องรู้ว่าไม่รู้อะไร จะได้ไปเติมสิ่งที่ขาดให้มันเต็ม และต้อง สั่งตัวเองเป็นด้วย เพราะอิสระมาพร้อมกับความรับผิดชอบสูงมาก
สุดท้ายถึงแม้ผมจะเพิ่งพูดเรื่อง Self-Driven ไป แต่ผมบอกเลยว่าผมผ่านมาถึงจุดนี้ไม่ได้เลย ถ้าผมไม่มีเพื่อนร่วมงานที่สุดยอดมากๆ ทุกคน ทุกบทสนทนา ทุกมุมมองต่างๆ ที่ผมได้รับการแบ่งปันมา ผมไม่รู้จะตอบแทนยังไงเลยนอกจากตั้งใจทำงานออกมาให้ดีที่สุดและหวังว่าซักวัน ผมจะได้แบ่งปันสิ่งที่ผมรู้กลับไปบ้าง

ปล.ผมชอบคำว่าต๊อกต๋อยมากเวลาได้ยินจากเพื่อนร่วมงานผม เวลาได้ยินแล้วรู้สึก Stand on the shoulder of giant มาก ฮ่าๆ