Review: DeepLearning.AI Data Engineering Professional Certificate

วันที่ 29 ธันวาที่ผ่านมาผมเพิ่งเรียนจบ DeepLearning.AI Data Engineering Professional Certificate มาครับ เป็น Coursera Specialization ตัวที่ 2 ในชีวิต หลังจากได้ตัวแรก Developing Application with Google Cloud เมื่อหลายปีมาแล้ว
แต่เอาจริงๆ ผมก็ไม่ได้ตั้งใจว่าจะเก็บเป็น Specialization อะไรหรอกครับ จุดเริ่มต้นของเรื่องราวนี้คือ ผมรู้จัก Joe Reis จากหนังสือ Fundamentals of Data Engineering มาก่อนหน้านี้แล้วกับ Subscribe newsletter ของเค้าด้วย พอช่วงประมาณเดือนสิงหาถ้าผมจำไม่ผิดนะ อาจารย์ Andrew Ng เปิดตัวเว็บ deeplearning.ai ขึ้นมา แล้วผมก็เหลือบไปเห็นคอร์ส Data Engineering ในนั้นมาว่าจะเปิดตัวเร็วๆ นี้ แถมสอนโดย Joe Reis อีก ผมรอจนถึงเวลาเปิดตัวแล้วเค้าก็เลื่อนเปิด จนช่วงปลายๆ เดือนกันยาถึงเปิด ผมก็เริ่มเรียนตั้งแต่วันแรกเลย

Course Format
ตัวคอร์สนี้จั่วหัวว่า Specialization สำหรับคนที่ไม่เคยเรียน Coursera ตัว Specialization หมายความว่าจะเป็นชุดคอร์สที่จะประกอบไปด้วยคอร์สย่อยๆ หลายคอร์ส ถ้าเรียนจบครบทุกตัว นอกจากเราจะได้ Certificate ของแต่ละคอร์สแล้ว เราจะได้ตัว Cert Specialization เพิ่มอีกด้วยครับ ซึ่งโดยตัว Specialization เองสามารถมองเป็น Learning Path ได้ด้วย เพราะจากประสบการณ์ผมแต่ละคอร์สที่เรียงมาให้จะ support ความรู้ให้เราต่อยอดใน Course ถัดๆ ไปได้ครับ
ซึ่งใน Specialization นี้จะแบ่งเป็น Course ย่อย 4 คอร์สคือ

ในแต่ละคอร์สย่อยจะใช้เวลาประมาณ 3-4 สัปดาห์แล้วแต่คอร์ส (แต่ส่วนใหญ่ 4 ยกเว้นคอร์ส 3) โดยในแต่ละสัปดาห์นั้น จะแบ่งเป็น Video Lecture ประมาณ 1.30 - 2 hrs ตามมาด้วย Lab Assignments 2-4 ตัว อันนี้แล้วแต่สัปดาห์เลย แล้วปิดท้ายด้วย Weekly Quiz 10 ข้อทุกสัปดาห์ โดยตัว Lab Assignment บางตัวกับ Weekly Quiz จะเป็นตัวตัด Grade ว่าเราจะเรียนผ่านหรือไม่ผ่านในตอนจบแต่ละคอร์สโดยต้องผ่าน 80% ขึ้นไปถึงจะผ่านในหัวข้อนั้นๆ
ด้วยความที่ตัวคอร์สวางตารางเป็นสัปดาห์ให้ทำให้แต่ละอาทิตย์จะมี Deadline ของแต่ละ Assignment, Quiz ที่ต้องเรียนให้จบภายในอาทิตย์นั้น แต่จริงๆ จะเกินก็ได้ แต่ส่วนตัวผมแนะนำว่าให้พยายามเรียนของแต่ละอาทิตย์ให้จบภายในอาทิตย์นั้น เพราะพอมันสะสมไปเรื่อยๆ มันเหนื่อยมากครับ (แค่พยายามเรียนให้จบแต่ละอาทิตย์ก็เหนื่อยละ)
สุดท้ายครับ ถ้าจะได้ Certificate กับทำ Lab ต้อง Subscribe Coursera ด้วยซึ่งอยู่ที่ $49 ต่อเดือนครับ ตั้งแต่เริ่มจนจบคอร์สใช้เวลาประมาณ 3 เดือนหรือ 15 สัปดาห์ ผมแนะนำมากๆ ว่าให้จัดสรรเวลาเรียนกับชีวิตดีๆ ครับเพราะมันกินเวลาประมาณ 3-6 ชม. ต่อสัปดาห์เลย แต่ไม่แนะนำให้เรียนอัดรวดเดียวครับ เพราะเนื้อหามันเยอะจริงๆ แล้วอาจจะไม่ค่อยได้อะไรกลับไป
Who should taking this course
ส่วนตัวผมที่เป็น Role Data Engineer มาเกือบๆ 3 ปีกับประสบการณ์ Software Engineer รวม 10 ปี ผมขอแบ่งคำแนะนำหัวข้อนี้ออกเป็น 2 กลุ่มใหญ่ๆ ละกันครับ
Beginner / Freshly Graduated
สำหรับมือใหม่ Specialization นี้ผมมองว่าเก็บภาพกว้างได้หมด ตั้งแต่ต้นน้ำ ไปจนถึงปลายน้ำในกลุ่มงาน Data Engineering ครับไล่ตั้งแต่เก็บ Business objective แปลงมาเป็น Technical Requirements มาจนถึงการเลือกใช้เทคโนโลยีแต่ละส่วน ไปจนถึงรูปแบบ data model ที่ส่งมอบตัวข้อมูลเพื่อไปใช้ประโยชน์ต่อไปครับ
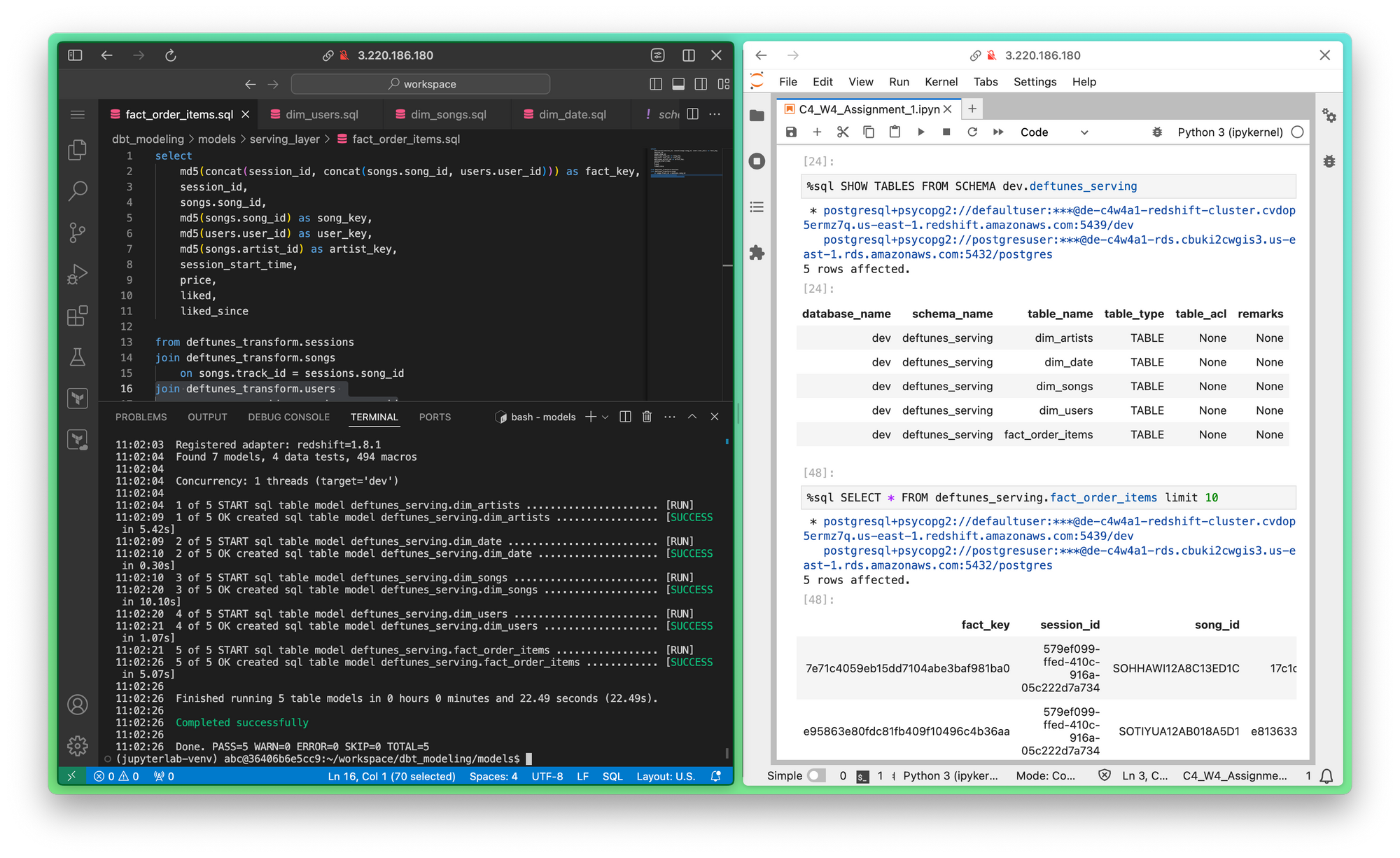
แต่ด้วยความที่มันไม่ใช่ Lecture นั่งฟังอย่างเดียวแต่มี Lab ด้วยทำให้ได้มีโอกาสได้ลองใช้เทคโนโลยีหลายๆ อย่างเพื่อประกอบเป็น data pipeline ทั้ง Batch, Streaming เพื่อเพิ่มความมั่นใจและความพร้อมในการจะไปทำงานต่อจริงๆ ด้วย
Experienced / Seasoned Engineer
ในส่วนของคนที่มือเปื้อนมาบ้าง ผมว่ามันเป็นการเติมเต็มส่วนที่ขาดมากกว่า เพราะในงานจริงๆ แต่ละบริษัทอาจจะเป็นได้ทั้ง Green field, Brown field แตกต่างกันไป ทำให้โอกาสที่เราจะได้ลอง Tooling / Pattern / Practice ต่างๆ อาจจะไม่ได้ครบทั้งหมดเช่น งานส่วนใหญ่อาจจะทำแต่ Batch processing pipeline ไม่ได้ทำ Streaming pipeline บ่อยๆ หรืออย่างเช่น การทำ Data modeling ให้แต่ละ data user ก็อาจจะตกเป็นงานของ Role อื่นอย่าง Analytic Engineer หรือ Data Analyst แทน ตัวคอร์สนี้เลยเข้ามาเติมเต็มในส่วนที่ขาดหลายๆ ส่วนให้เราได้กลับมารื้อฟื้นปัดฝุ่นความรู้เรา ว่าของพวกนี้ควรจะออกแบบยังไง ส่งมอบยังไงครับ
ต่อไปเป็นรายละเอียดแต่ละคอร์สจากประสบการณ์ผมเองครับ
Course 1: Introduction to Data Engineering
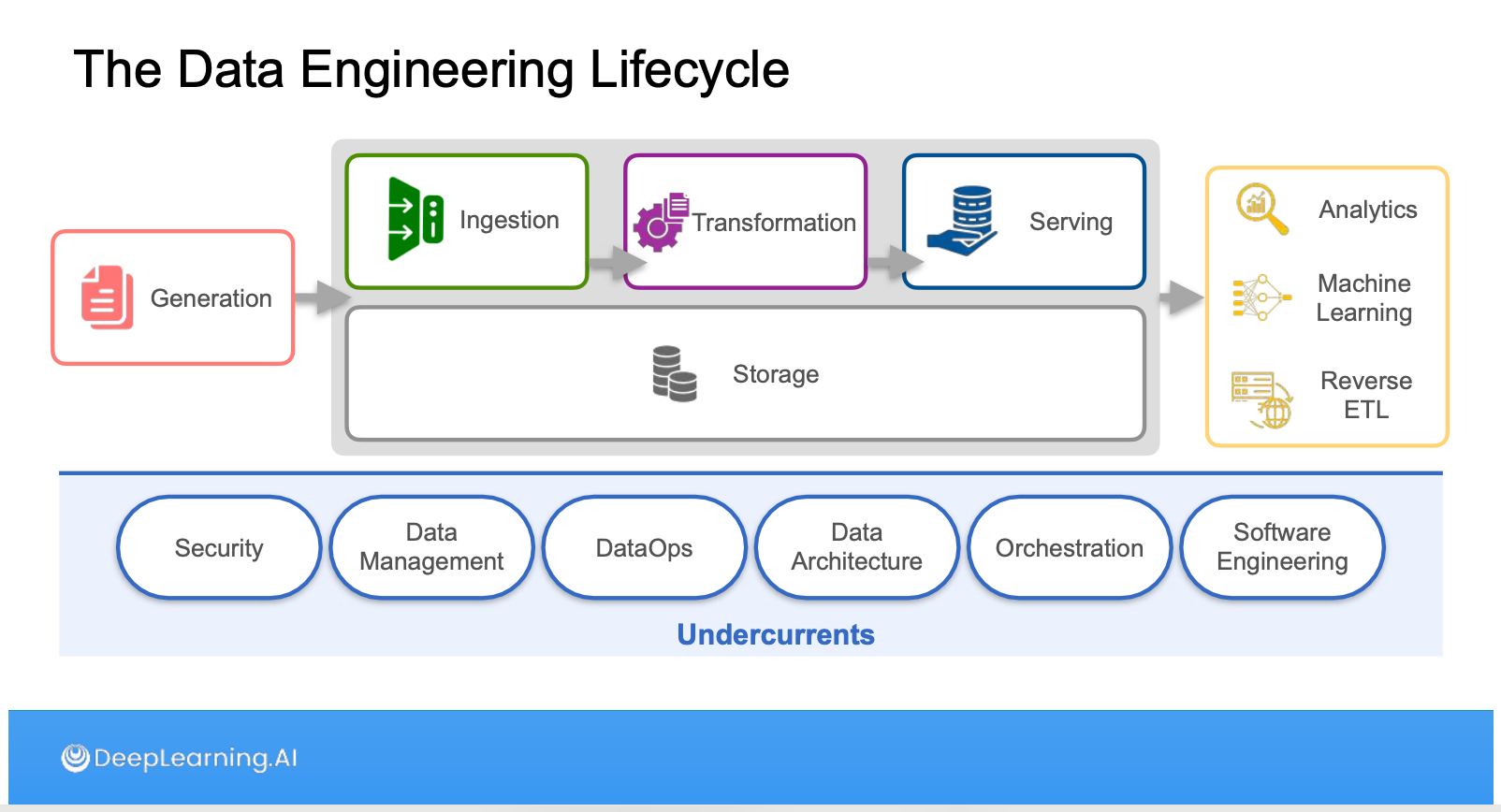
สำหรับคอร์สแรกนี้พอมามองย้อนกลับไป ก็ยังคงใช้คำเดิมว่ามันคือความ Overview และ Definition ครับ เพราะคอร์สแรกจะพาเราไปรู้จักนิยามต่างๆ ของคำที่เกี่ยวข้องใน Data Engineering Field แล้วต่อด้วยพระเอกอย่าง Data Engineering Life Cycle ครับ
ตัว Life Cycle พยายามจะวางกรอบงานและเครื่องมือให้อยู่ในรูปแบบเดียวกัน แต่ก็ยังไม่ละองค์ประกอบที่จำเป็นอื่นๆ ในการทำงานเพราะ Data Engineering ก็เป็น kind of Software Engineering แบบนึง ในส่วนของ Undercurrent เลยเป็นส่วนที่ อาจจะไม่อยู่ในรูป flow หลัก แต่เป็นองค์ประกอบที่ขาดไม่ได้ที่เติมเต็มให้ flow หลักทำงานได้ดี
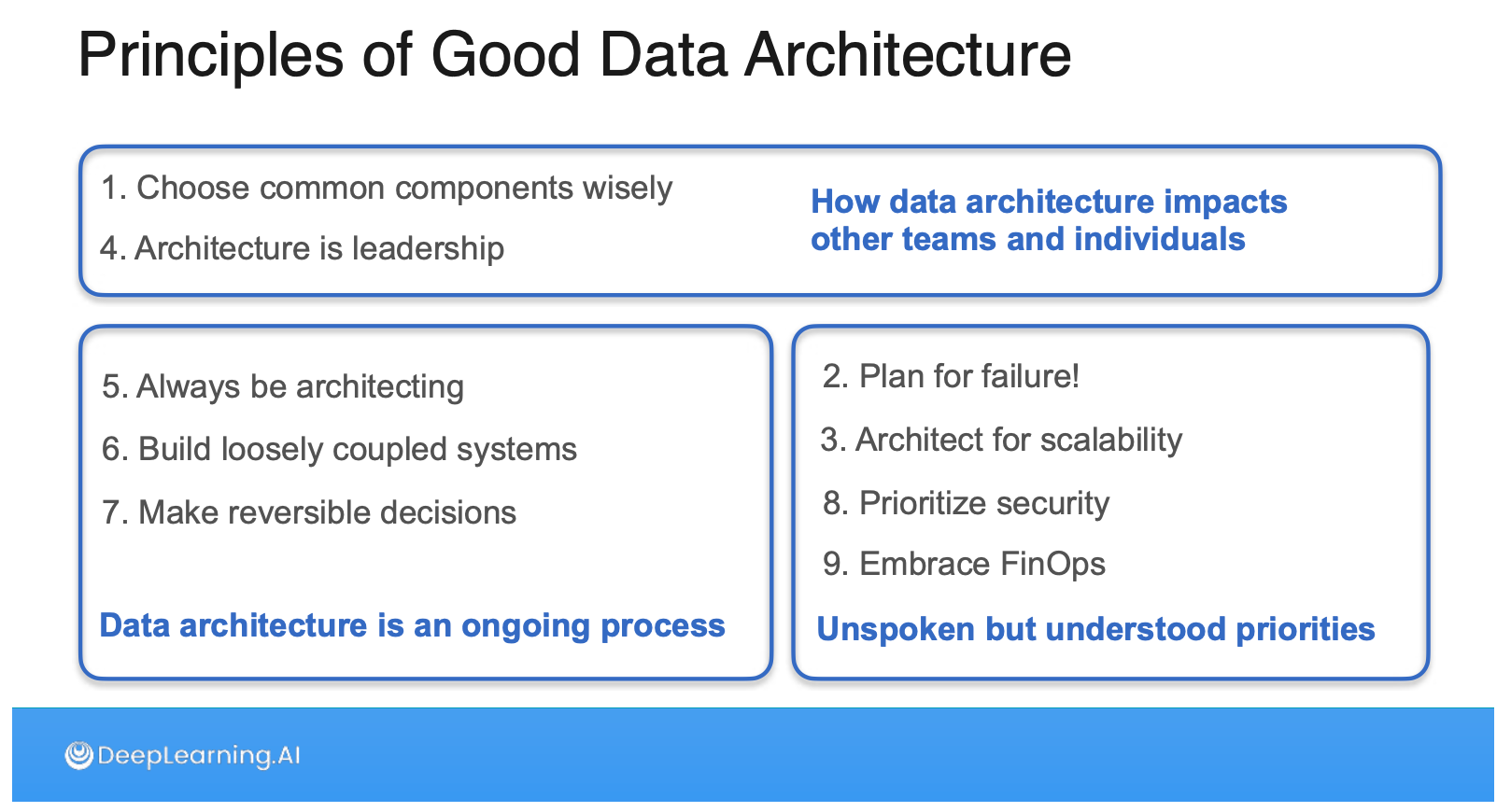
ด้วยความที่คอร์สนี้มีความ Partner กับ AWS ด้วย ส่วนหนึ่งของคอร์สแรกคือการ Intro ให้รู้จัก AWS ด้วยครับ ซึ่งพาให้เราไปรู้จักกับ Well-architected Framework ที่เป็นเซ็ตของคำถามให้เราคิดเวลาเราจะ implement อะไรบน Cloud แต่ที่เสริมขึ้นมาด้วยความเป็นคอร์ส Data Engineering คือการแนะนำให้เรารู้จักสิ่งที่เรียกว่า Principles of Good Data Architecture ครับ ส่วนตัวผมชอบ Section นี้มาก เพราะจากประสบการณ์มันคือเรื่องสำคัญแต่ไม่ใช่ Hard work แต่เป็น Soft work ที่ต้องทำคู่ไปด้วยเพื่อจะทำให้งานหลักออกมาดี
ในส่วนสุดท้ายของคอร์ส 1 จะพาเราไปแมพความรู้ของ Data Engineering Life Cycle กับวิธีคิดของ Data Engineer ออกมาเป็น Requirements ที่เราจะเอาไปทำงานต่อครับ ซึ่งดีมากๆ ใครยังรับงาน Data Engineer แต่ไม่รู้จะเก็บ requirements ออกมาให้เป็นรูป เป็นร่างยังไง ผมแนะนำในส่วนของสัปดาห์ที่ 4 คอร์สนี้เลย
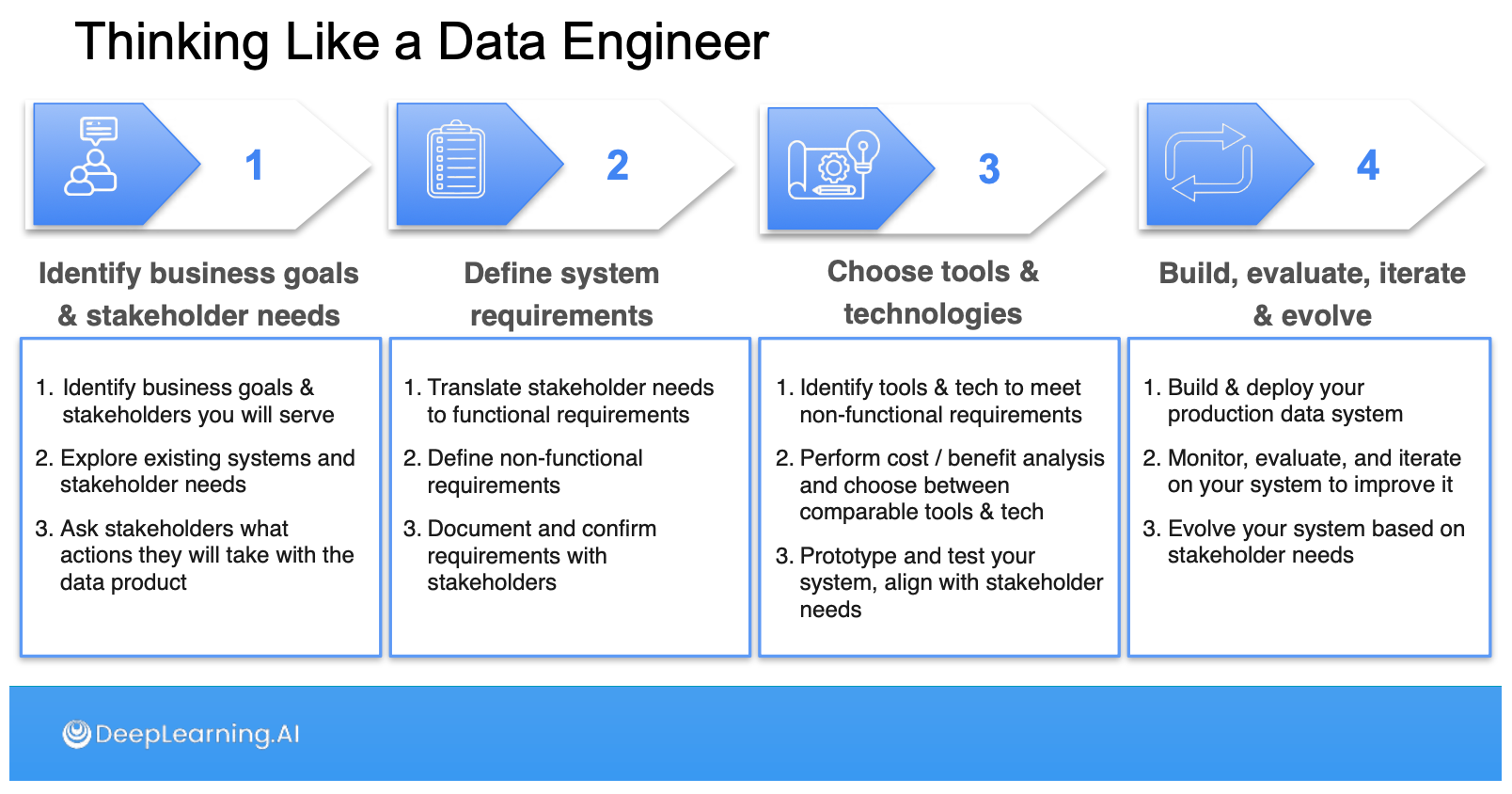
Course 2: Source Systems, Data Ingestion, and Pipelines
พอเรารู้จักภาพกว้างในคอร์สแรกแล้ว คอร์สสองตัวนี้จะพาเราไปลงลึกใน 2 ก้อนแรกของ Data Engineering Life Cycle คือ Data Generation, Ingestion แล้วเสริมด้วย Undercurrent ทั้ง Security, DataOps, Orchestration ครับ
ส่วนของ Source System ก็คือ Data ต้นน้ำที่เราต้องไปทำงานด้วยในคอร์สนี้พาไปรู้จักทั้งในแกน Structured, Semi-Structured, Unstructured Data และลงลึกไปแต่ละประเภทอีกทั้ง Database (Relational, NoSQL) ที่เล่าไปจนถึง ACID Compliance หรือประเภทอย่าง Object storage, REST API, Logs เรื่อยมาจนถึง Streaming System
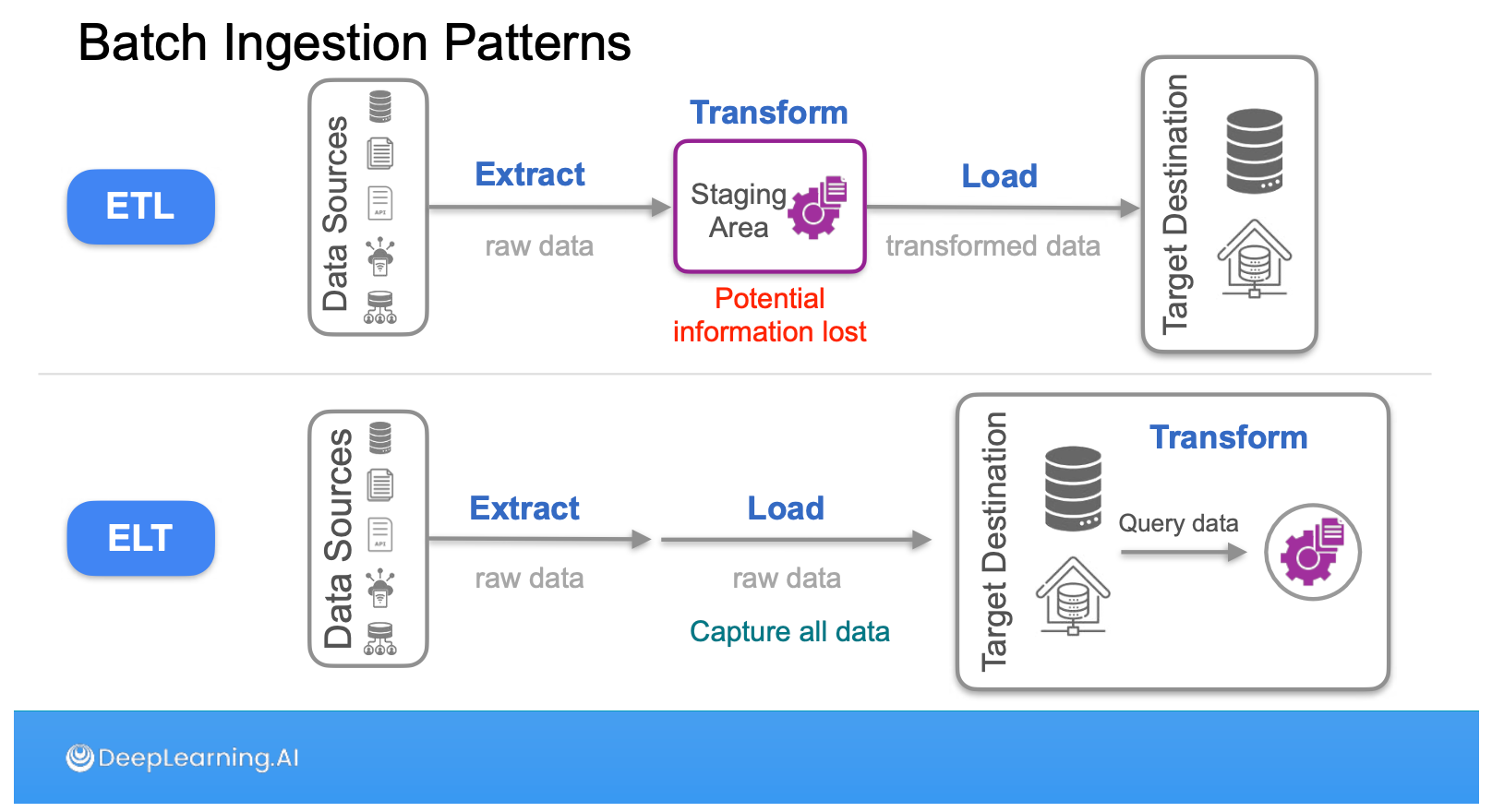
ส่วนของ Data Integration นี่จะลงใน Pattern ที่จะอยู่ในกรอบของ frequency ไล่ตั้งแต่ Batch, Micro-batch ไปจนถึง Streaming หรือจะมองในมิติ ETL vs ELT ว่ามีข้อดี ข้อเสียต่างกันยังไง แล้วด้วยความที่คอร์สนี้พื้นฐานอยู่บน AWS เราจะได้ใช้ components อย่าง AWS Glue Job, AWS Kinesis ในการทำแล็บ Data Integration ด้วยครับ
ส่วนของ Undercurrent ในมุมของ Security คือพาไปรู้จัก IAM Security กับ AWS Networking ว่าจะ control ยังไงรวมไปถึงหัด debugging ปัญหา ACL ใน AWS ด้วย ส่วนของ DataOps ในส่วนของทฤษฏีจะแบ่งเป็น 3 pillars: Automation, Observability & Monitoring, Incident Response
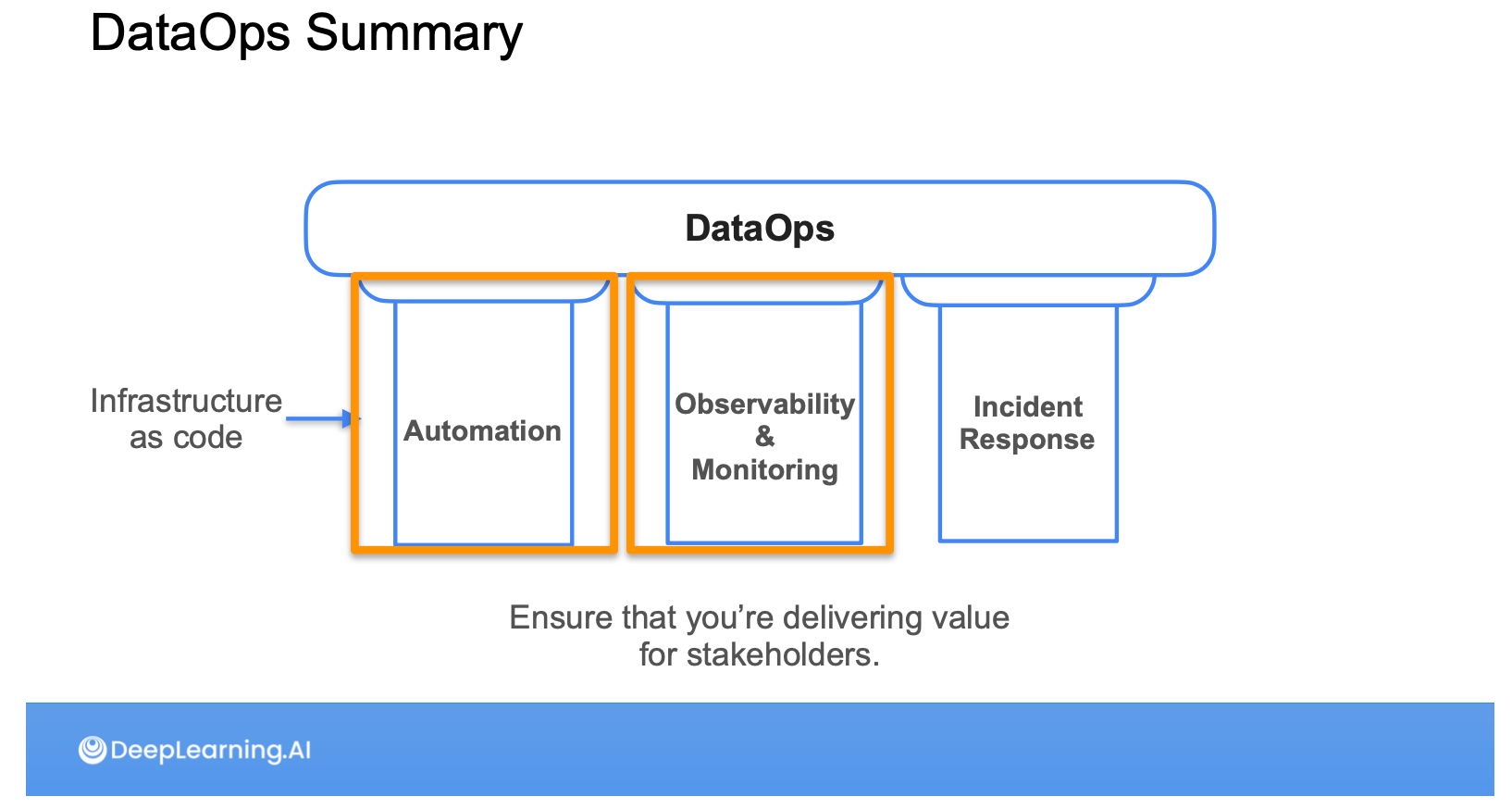
โดย Automation จะเน้นไปที่การใช้ Terraform มาช่วย Provision component ต่างๆ ใน AWS แบบ Infrastructure as a Code (IaaS) และ Observability & Monitoring จะเน้นไปที่การใช้ Great Expectation มาช่วยทำ Data Quality กับ AWS Cloudwatch ในการทำ Monitoring ครับ
ในส่วนสุดท้ายของคอร์สนี้คือ Data Orchestration / Pipelines จะสรุปง่ายๆ ว่าไปเรียน Airflow ก็ได้ครับ แต่จะลงไปตั้งแต่ Cron, DAGs, และพาไปรู้จักองค์ประกอบของ Airflow server เรื่อยไปจนถึง API ของ Airflow เช่น Operators, XCom, Variables หรือ TaskFlow API
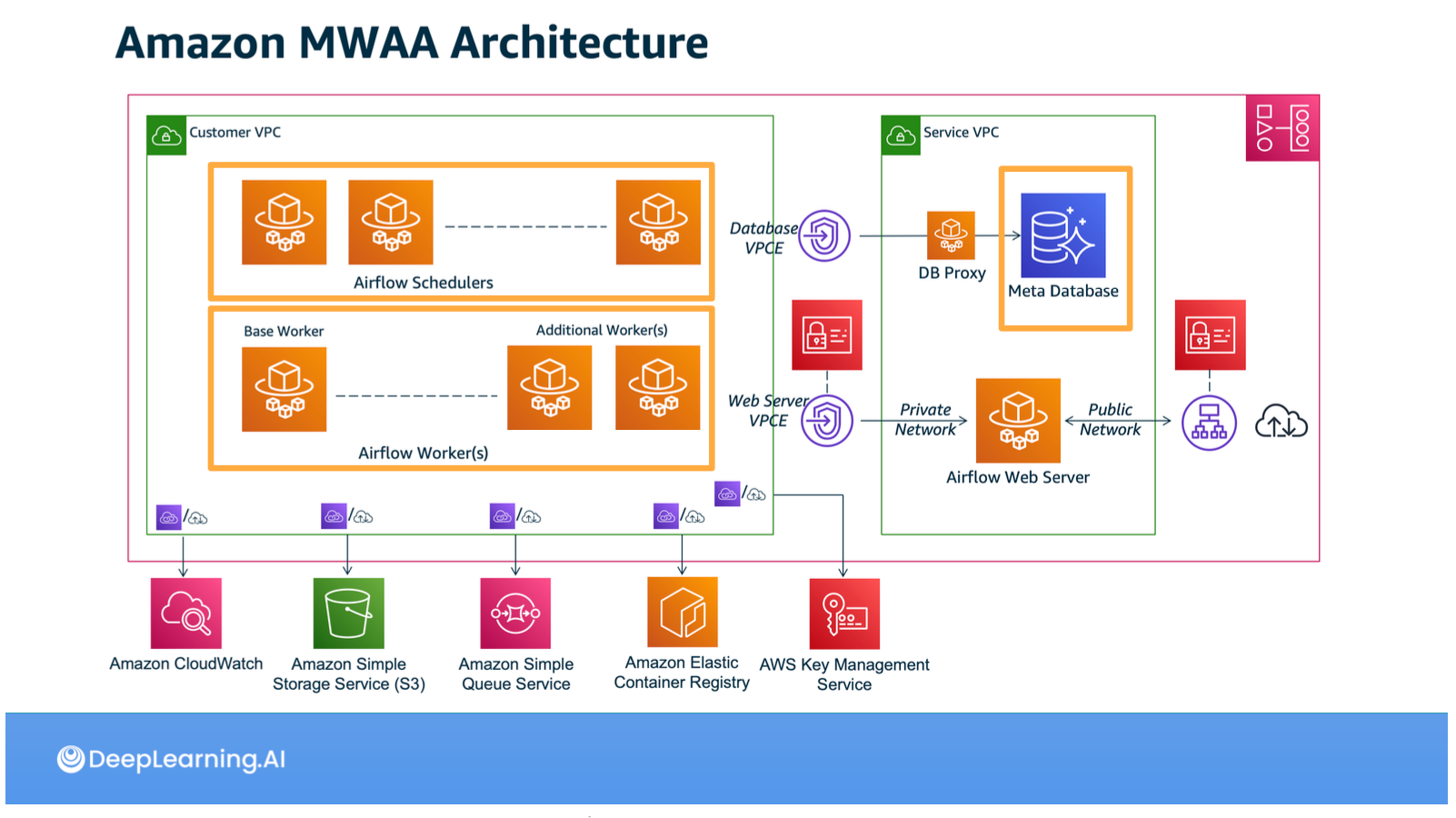
พอมามองย้อนกลับไป Course 2 นี่มันเนื้อหาเยอะจนร้องขอชีวิตจริงๆ แหะ
Course 3: Data Storage and Queries
ถ้าคอร์ส 1 กับคอร์ส 2 คืองานที่เราจะได้ทำจริงๆ เป็นการวางองค์ประกอบให้แต่ะละส่วนประสานงานกัน Course 3 นี่ผมเปรียบว่าเป็นรากฐานที่ทำให้ 1+2 ทำงานได้ครับ โดยในคอร์สนี้จะเน้นไปที่การทำงานและการเลือกใช้ Storage ของ data ที่เราดึงมาจาก Source Systems แล้วครับ
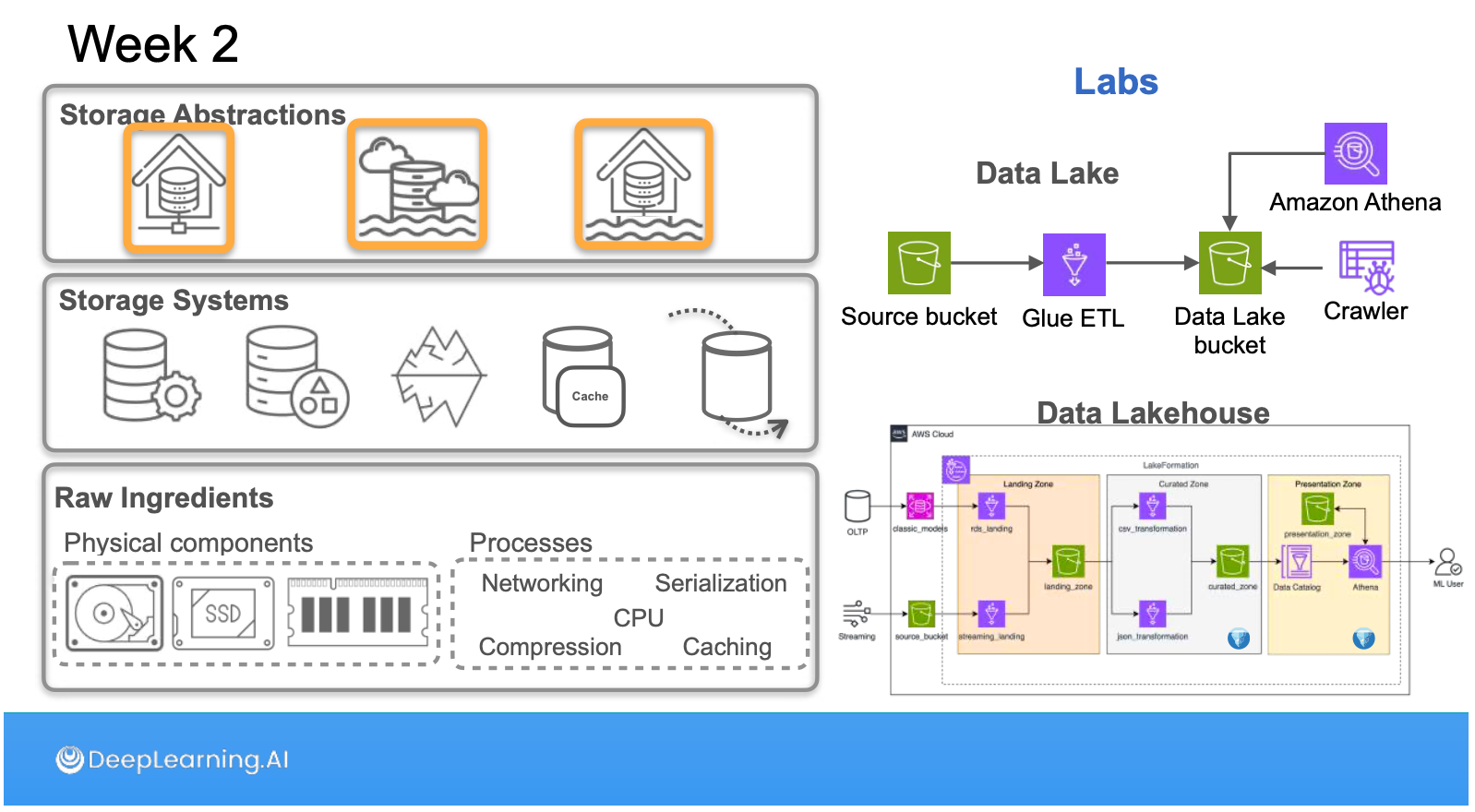
โดยเนื้อหานี่ไล่ตั้งแต่ Physical storage อย่าง Magnetic Disk, SSD, RAM, CPU Cache ขึ้นมาเป็น Logical storage อย่าง File Hierarchy, Block Storage, Object Storage มาจนชั้น Application storage อย่าง Key-value in-memory, Rows, Columnar, Graph, Vector
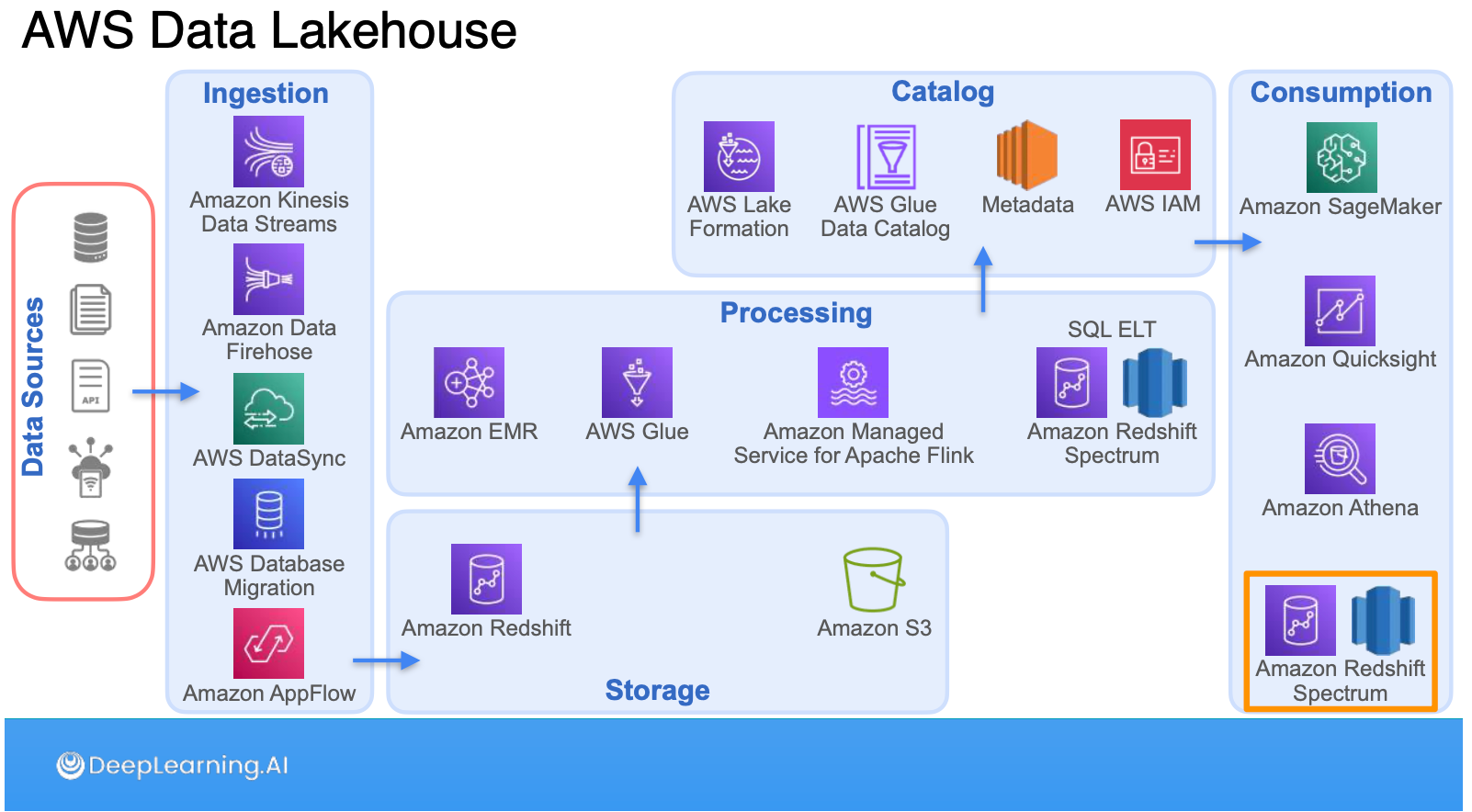
พอ components แน่นแล้วก็ยกระดับขึ้นมาเป็น Abstraction อย่าง Data Warehouse, Data Lake, Data Lakehouse ซึ่งไม่ใช่แค่ Abstraction ที่พูดถึง แต่ยังลงไปที่ tooling ที่ช่วยให้มันเกิดขึ้นได้อย่าง MPP (Redshift), Open table format (Iceberg) ด้วยครับ
และแน่นอนว่าเราจะพูดถึง Application Storage โดยไม่พูดถึง Queries ไม่ได้ครับ ใน ส่วนนี้นั้นเรียกได้ว่าเขียน Queries จนต้องร้องขอชีวิตตั้งแต่ basic อย่าง select, from, where, join, aggregation เรื่อยไปจน advance statement อย่าง SQL Functions, CTEs, condition expression, sub-queries, และ Sliding windows ครับ นอกจากนี้ยังพาเราไปรู้จักกับเทคนิคการ Optimize queries บน database อย่างการ Index บน RDBMS หรือ Sort key บน Columnar DB และปิดท้ายด้วยการเขียน Queries บน Streaming System โดยอาศัย Window pattern หลายๆ แบบครับ
Course 4: Data Modeling, Transformation, and Serving
พอผ่านคอร์ส 1-3 มาเราจะเริ่มมีไอเดีย, เครื่องมือและเทคนิคแล้วว่าจะพา Data จากจุด A → B ยังไง ในส่วนของคอร์ส 4 จะเป็นเรื่องของการวาง Model ของ Data เพื่อให้ Downstream system หรือ Data User เอา Data ไปใช้งานได้ง่ายและเกิดประโยชน์สูงสุดครับ
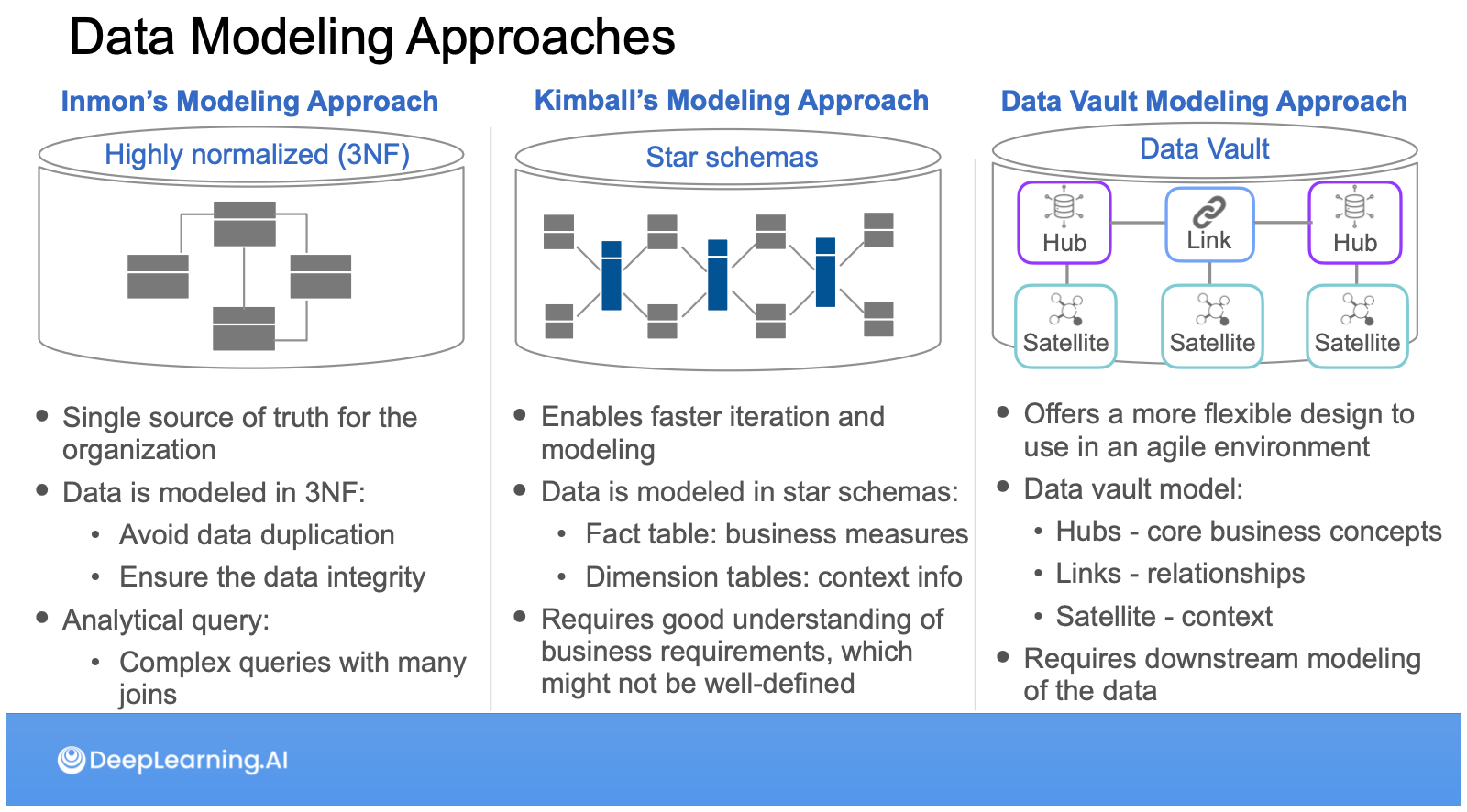
พาร์ท Data Modeling นี่ส่วนหนึ่งเหมือนกลับไปเรียนวิชา Database สมัยมหาลัยมาก ไล่ตั้งแต่ Normalization (1NF → 3NF), Star Schema แต่ก็เพิ่งรู้ว่าในโลก Data Warehouse เค้าแบ่งกันเป็น 2 ค่ายคือ ค่าย Inmon ที่เน้น Join ทำ 3NF กับค่าย Kimball ที่เน้นการวาง Star Schema ซึ่งในคอร์สนี้ไล่ให้เห็นแต่ละแบบเลยว่ามีข้อดี ข้อเสียยังไงบ้าง นอกจากนี้ยังมีค่ายที่ 3 อย่าง Data Vault ที่แบ่ง Model เป็น Hub, Link, Satellite ด้วย รวมไปถึงเทคนิคที่ง่ายที่สุดอย่าง One Big Table (OBT) ด้วย ซึ่งเราจะได้ฝึกการวาง Data modeling เหล่านี้ผ่านเครื่องมืออย่าง dbt ด้วยครับ
ในส่วนของ Data Modeling ยังมีอีกส่วนคือการเตรียม Data ของเราเพื่อสนับสนุนการทำ Feature Engineering ใน ML Project Lifecycle Framework ครับ ทั้งในส่วนที่เป็น Numerical data อย่าง Handling missing, Scaling Numerical, Encoding หรือส่วนของ Text data อย่าง Cleaning, Normalization, Tokenization, Remove stop words, Lemmatization ซึ่งในแล็บได้เขียน Pandas กับ Scikit-learn เตรียม data อย่างเมามันครับ
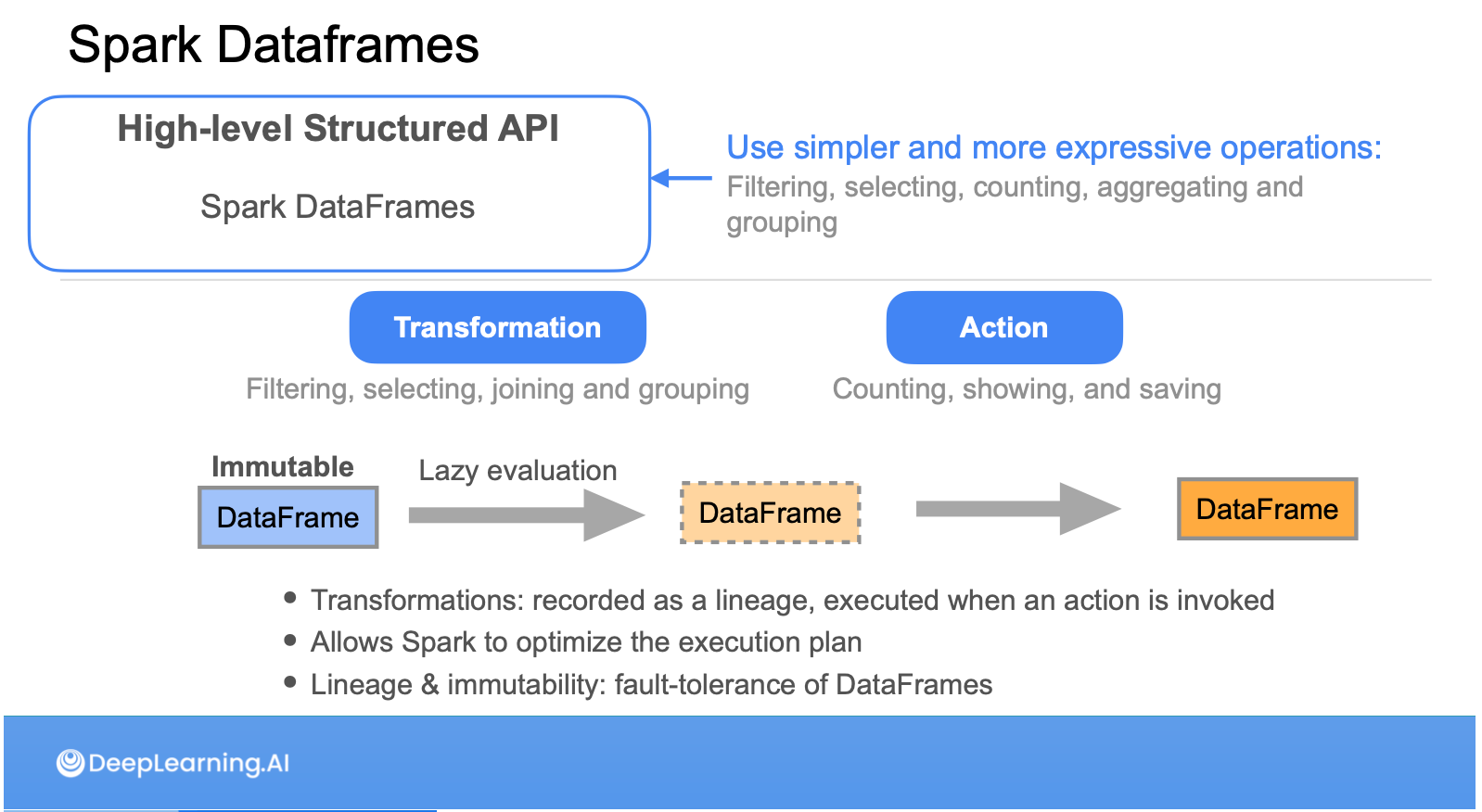
พอเข้าเนื้อหา Data Transformation จะเป็น Transformation ในส่วนของปลายน้ำมากกว่าตอนที่เราทำ Data Ingestion ครับ โดยจะพูดถึงเทคนิคอย่าง Truncate & Reload, Capture update, Capture delete มีแวะมาเล่าเรื่อง Hadoop ให้เราเข้าใจก่อนจะยกระดับไปถึง Spark แล้วเน้นไปที่การเลือกใช้ระหว่าง Spark UDF, DataFrame API, Spark SQL และ Spark Streaming
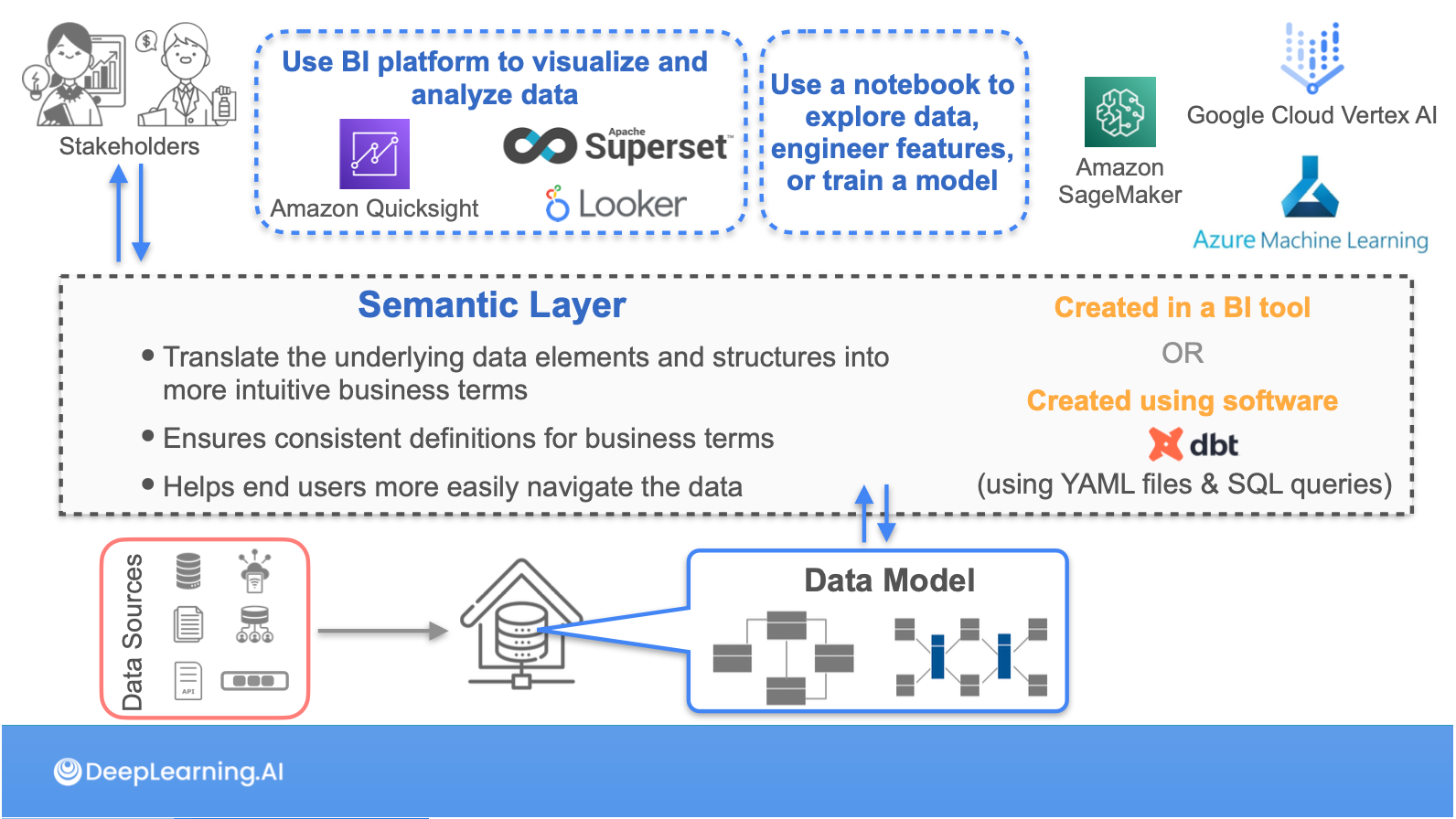
ในส่วนสุดท้ายของคอร์ส Serving จะย้ำเราถึงรูปแบบของการส่งมอบครับว่าจะทำยังไงถึงจะส่งมอบ Data แต่ยัง Compliance กับ Data Management อยู่ ซึ่งแต่ละ Use case ทั้ง Analytics, ML ก็จะมีความต้องการรวมถึงรูปแบบที่แตกต่างกัน เลยต้องเกิดสิ่งที่เรียกว่า Semantic Layer ขึ้นมาขั้นอีกชั้นนึง ซึ่งตัว Semantic Layer นี้จะ Implement ในรูปแบบของ View / Materialize View / Dataset ใน Superset แตกต่างกันไปแต่ละ Use case ครับ
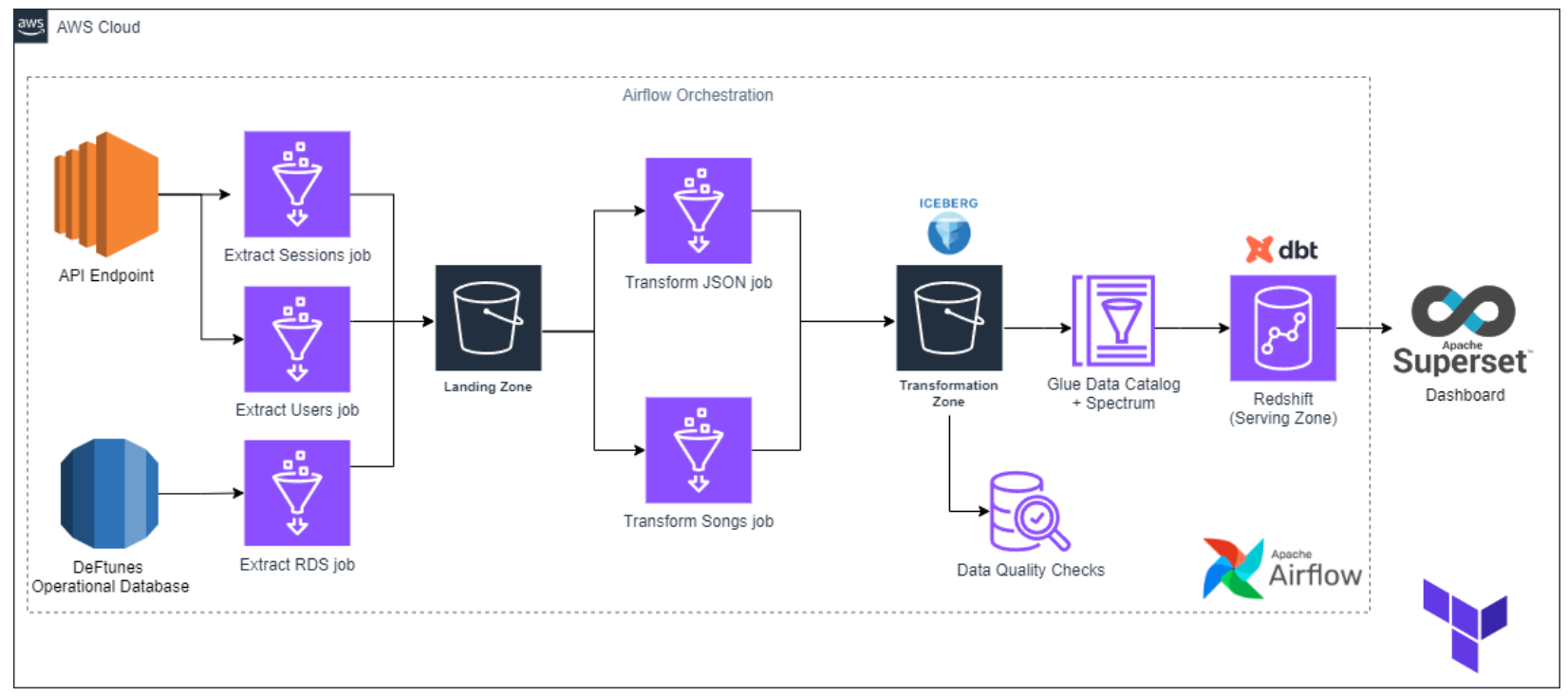
ตัวคอร์ส 4 จะจบด้วย Capstone project ครับ เป็นเหมือนการทวนเราอีกรอบให้เราใช้ความรู้ตั้งแต่ต้นน้ำการเก็บ requirements เลือกเทคโนโลยีทำ data pipeline โดย Ingest และทำ Data Quality check ผ่าน component บน AWS อย่าง Glue, transforms เป็น Star Schema ผ่าน dbt แล้ว Serving ด้วย Superset โดยทั้งหมดถูก Orchestrate ผ่าน Airflow
จบแล้วครับ ขอบคุณทุกคนที่อ่านจนจบ ถ้าเขียนไม่ค่อยรู้เรื่องกราบขออภัยเพราะเนื้อหามันเยอะจริงๆ อยากบอกว่าเป็น 3 เดือนที่ได้ความรู้เยอะมาก ล้นมาก แล้วผมมั่นใจมาก ว่าที่ผมเขียนไว้ข้างบนก็ยังเก็บมาไม่หมดกับความรู้ที่ผมได้มาในคอร์สนี้ครับ ถ้าใครตัดสินใจเรียนแล้วขอให้เรียนให้จบครับ มันคุ้มมากกับเวลาที่เสียไป แล้วถ้าใครเรียนจบแล้วเหมือนกัน ขอแสดงความยินดีด้วยคนครับ ถึงใครจะไม่รู้ แต่รู้ไว้ว่าผมคนนึงที่เข้าใจความตั้งใจและเหนื่อยยากในการผ่าน 3 เดือนนี้มาได้ สวัสดีครับ
